

INTRODUCTION –
Apache Solr is a NoSql based text search engine with the capacity to run blazing fast searches along with loads of functionalities such as faceting, grouping, collapsing, fuzzy searching, boosting, relevancy tuning, etc. Its an extrapolation of Lucene-based search and is developed based on the open-source architecture.
Most businesses these days need their customers to have a holistic experience leading to higher conversion rates, better sales, and a more robust market presence. To facilitate this, we not only need a fully functional backend but also need state-of-the-art pipelines. In the process, Apache Solr serves as a good resource to facilitate all search-based operations a business might utilize. Come to think of it, Solr integration to any website can offer an enhanced experience for the end customer.
For instance, users might need to query data as simple as “Brown shoes”. Solr provides the necessary tools to make this search robust (by utilizing edismax/ other state-of-the-art parsers), elaborate(result set can have descriptions set for product SKU’s), pin-pointed(based in user’s geographical location searches are constricted to that area), relevant and after some recent changes, quite futuristic (essentially by utilizing AI/ML libraries).
Let’s try and understand this through a use-case.
ENTERPRISE SEARCH FOR A JOB SEARCH AGENCY
In this case, we will go through a case study for the job search agency, and how it can benefit from using Apache Solr as an enterprise search platform.
Problem statement
In many job portal agencies, the enterprise search helps reduce the overall time employees spend in matching the expectations from customers with the resumes. Typically, for each vacancy, customers provide a job description. Many times, the job description is a lengthy affair, and given the limited time each employee gets, he has to bridge the gap between these two. A job search agency has to deal with various applications as follows:
- Internal CMS containing past information, resumes of candidates, etc
- Access to market analysis to align the business with the expectation
- Employer vacancies may come through e-mails or an online vacancy portal
- Online job agencies are a major source for supplying new resumes
- An external public site of the agency where many applicants upload their resumes
Since a job agency deals with multiple systems due to their interaction patterns, having a unified enterprise search on top of these systems is the objective to speed up the overall business.
Approach
Here, we have taken a fictitious job search agency that would like to improve the candidate identification time using enterprise search. Given the system landscape, Apache Solr can play a major role here in helping them speed up the process. The following screenshot depicts the interaction between unified enterprise searches powered by Apache Solr with other systems:
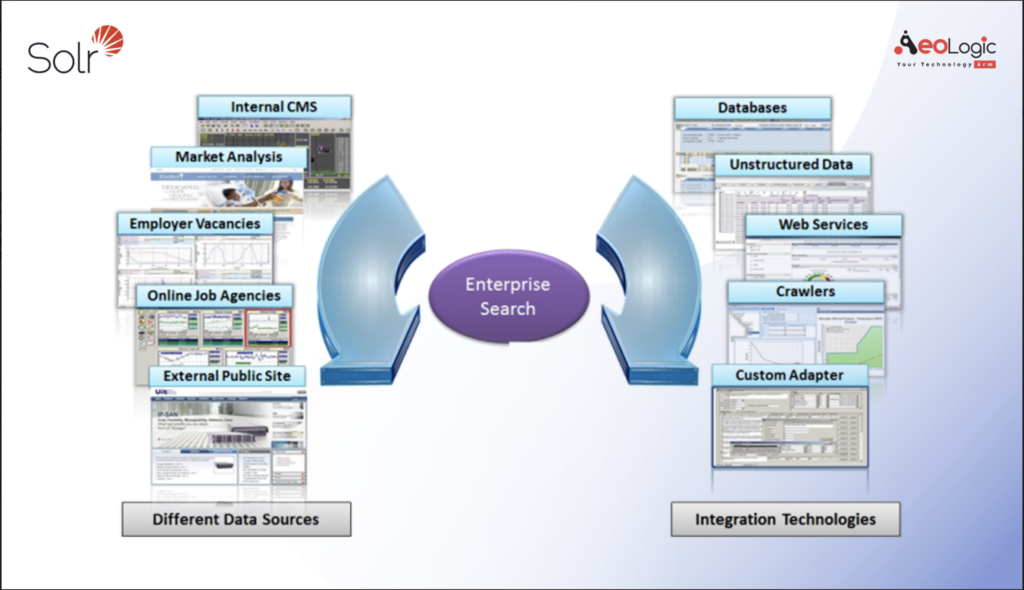
The figure demonstrates how enterprise search powered by Apache Solr can interact with different data sources. The job search agency interacts with various internal as well as third-party applications. This serves as input for Apache Solr-based enterprise search operations. It would require Solr to talk with these systems by means of different technology-based interaction patterns such as web services, database access, crawlers, and customized adapters as shown on the right-hand side. Apache Solr provides support for the database; for the REST, the agency has to build an event-based or scheduled agent, which can pull information from these sources and feed them in Solr. Many times, this information is raw, and the adapter should be able to extract field information from this data, for example, technology expertise, role, salary, or domain expertise. This can be done in various ways. One way is by applying a simple regular expression-based pattern on each resume, and then extracting the information. Alternatively, one can also let it run through the dictionary of verticals and try matching it. A tag-based mechanism also can be used for tagging resumes directly from the information contained in the text.
Based on the requirements, now Apache Solr must provide rich facets for candidate searches as well as job searches, which would have the following facets:
- Technology-based dimension
- Vertical- or domain-based dimension
- Financials for candidates
- Timeline of candidates’ resume (upload date)
- Role-based dimension
This is how we can substantiate the tasks necessary with Solr.


